Una pregunta muy común para los iniciados en el mundo de SQL Server, es cuál es la diferencia entre un índice clustered y un índice non-clustered y en qué caso conviene usar un índice u otro. Bueno, empecemos a describir las características generales de un índice y luego de estos tipos de índices y las conclusiones van a ser evidentes.
Los índices son objetos de la bases de datos, cuya función es optimizar el acceso a datos. A medida que las tablas se van haciendo más grandes y se desea hacer consultar sobre estas tablas, los índices son indispensables.
Internamente un índice normal es una estructura de árbol, que cuenta con una página principal y luego esta con paginas hijas, que a su vez tiene más paginas hijas hasta llegar a la pagina final del índice (leaf level).
La clave del índice está repartida en las páginas del índice, de modo tal que la búsqueda se haga leyendo la menor cantidad posible de datos.
Estructura interna de un índice:
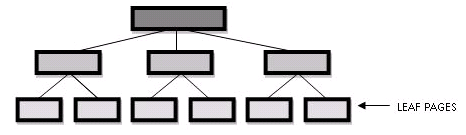
Después de esta brevísima introducción, donde está la diferencia entre un índice clustered y uno non-clustered? En la leaf level (la ultima pagina) del índice. En un índice non-clustered, la clave por la que buscamos tiene un puntero a la página de datos donde se encuentra el registro. Mientras que en índice clustered, la leaf level es la pagina de datos!. Con lo cual, el SQL Server, se ahorra hacer un salto para leer los datos del registro (Bookmark lookup). La diferencia es importante, ya que el uso de este tipo de índices al evitar tener que hacer lecturas adicionales para traer el registro, son más performantes.
Búsqueda por clustered index: | Búsqueda por non-clustered index: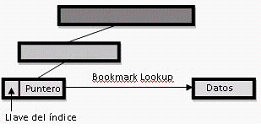 | |
| SQL Server 2005 incorpora una nueva feature interesante en los índices non-clustered. Ahora es posible incluir dentro de la leaf page del índice, campos que en sí, no son parte de la clave. Esto nos permitirá en algunos casos, evitar el salto a la página de datos (Bookmark Lookup) que habíamos hablado anteriormente. Aunque hay que tener cuidado de seleccionar bien que campos se desean incluir al índice, porque de poner demasiados se expandería mucho el índice, haciendo ineficiente. Por ejemplo, si tenemos una tabla Personas cuyo campo DNI es un índice non-clustered y queremos hacer una consulta que solo traiga el Apellido y DNI, entonces si incluimos el campo Apellido , nos ahorraríamos tener que ir a la página de datos para buscar el valor. Es importante recalcar que el campo Apellido no sería parte de la tabla, sino un campo mas en pagina final del índice. |
Por lo tanto, en tablas grandes y muy consultadas, tenemos que ser cuidadosos y analizar a que campos vamos a seleccionar para ser llaves del índice clustered. Tenemos 1 solo índice de este tipo por tabla, no hay que desperdiciarlo!!!
Este último punto es importante para saber en qué situaciones y para que campos se debe utilizar un clustered index o un non-clustered.
Guía general de uso de índices:
- Campos autoincrementales (Identitys, newsequentialid, etc), deben convenientemente ser del tipo clustered index. La razón es reducir el page split (fragmentación) de la tabla.
- Los clustered index son convenientes si se va seleccionar un rango de valores, ordenar (ORDER BY) o agrupar (GROUP BY).
- La PK es un buen candidato para un clustered index. Pero no siempre. Por ejemplo, si tenemos una tabla de ventas, cuya PK es un identity en donde se efectúan muchas consultar por rangos de fecha, el campo Fecha seria un mejor candidato para el clustered que la PK.
- Para búsquedas de valores específicos, conviene utilizar un non-clustered index.
- Para índices compuestos, mejor utilizar non-clustered index (generalmente).
No hay comentarios:
Publicar un comentario